DDQ & RFP Autofill · IR & RFP Teams
The DDQ is not
the bottleneck.
The right answer is.
Every AI tool in this space promises faster responses. We asked a different question: what would it take to produce a DDQ or RFP response that actually reflects your firm's positioning — accurately, consistently, every time it's asked?
The problem IR teams don't talk about openly
Ask any IR or RFP team about their DDQ process and they'll describe the same thing: a response from a fund document that gets copied, answers that get pulled from memory or a previous DDQ response, a frantic search through old documents when a question doesn't look familiar, and a final review that amounts to hoping nothing has drifted too far from what was said last time.
The volume of DDQs and RFPs has grown. The questions have become more granular — on ESG, on operational infrastructure, on risk, on AI, on fees. Allocators are comparing responses across managers with increasing rigour. And yet most IR teams are still responding the way they did five years ago: manually, inconsistently, under deadline pressure.
The real pain is not speed. It's that the same question, asked six months apart, gets a subtly different answer. And in a due diligence process, subtle inconsistencies are exactly what trained allocators are looking for.
"The same question, asked six months apart, gets a subtly different answer. In a due diligence process, that inconsistency is what allocators are trained to find."
Why DiligenceVault sees this differently
Most tools in this space are built by technology companies looking at the DDQ as a document problem. DiligenceVault is built by a team that sits on both sides of this workflow. We understand what allocators are looking for when they send a DDQ — because we work with allocators every day. And we understand what IR teams are dealing with when they respond — because we work with asset managers and GPs who live this process.
That dual vantage point changes what we built. We didn't set out to make DDQ completion faster. We set out to make DDQ responses something an allocator trusts — because they're accurate, sourced, and consistent with everything else the firm has communicated.
Speed is a byproduct of getting that right. It is not the goal.
Context: the source layer that changes everything
The reason most AI tools produce unreliable DDQ responses is not a model problem. It's a context problem. When a tool doesn't have access to verified firm data, it does one of two things: it drafts from scratch using general language that sounds plausible but isn't accurate, or it relies on whatever the user pastes in, which is only as good as the user's recollection, or sometimes riddled with conflicts.
DiligenceVault's autofill draws from a proprietary source layer — the firm's own verified data infrastructure, not a generic knowledge base.
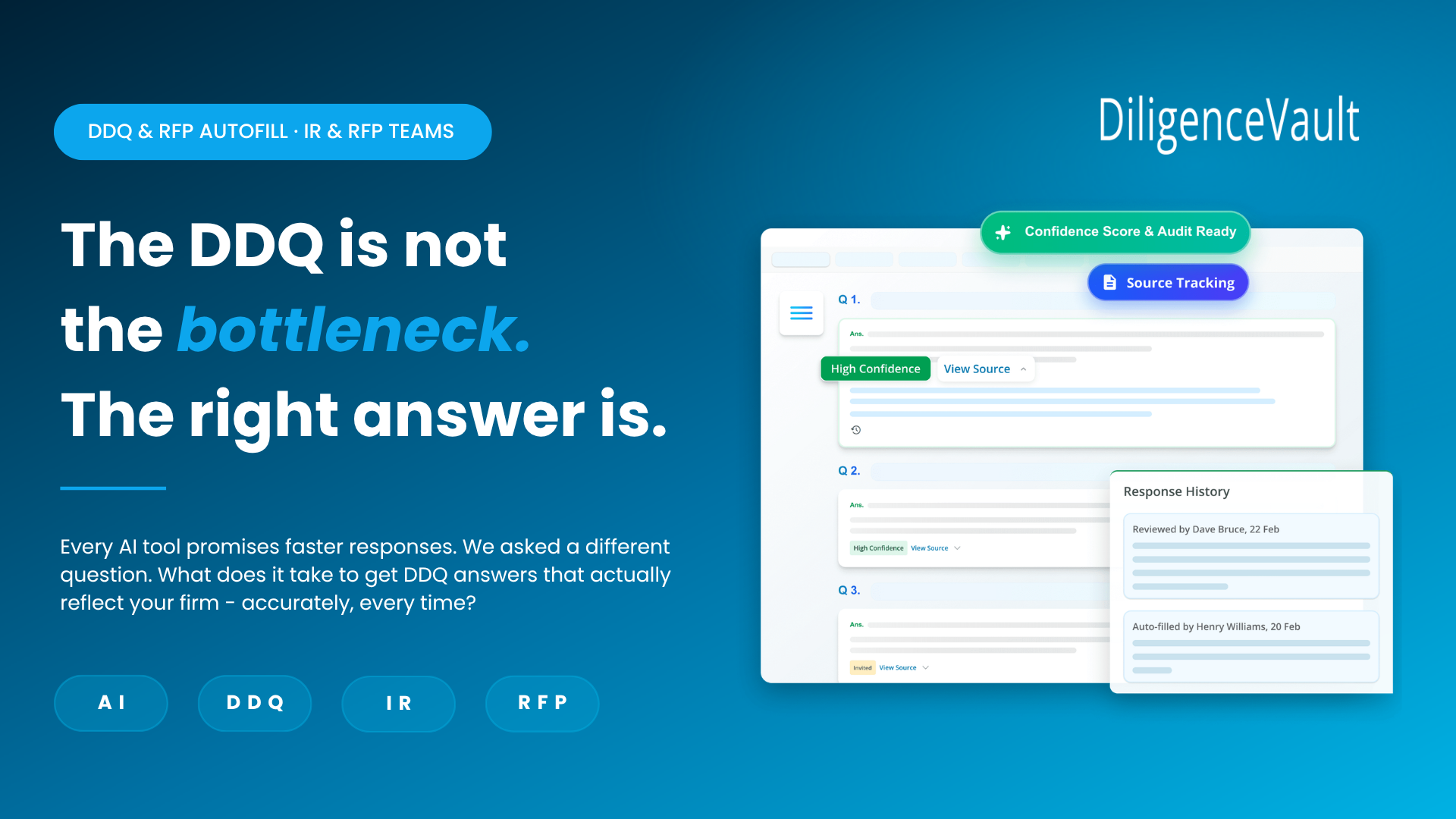
When an autofill is triggered, the system doesn't guess. It retrieves. Every answer is drawn from verified source material, with a citation trail that shows exactly where the response came from. If the source material doesn't support an answer, the system flags the gap — it doesn't fill it with plausible-sounding language.
This is the structural advantage DiligenceVault delivers by surfacing gaps honestly.
Skills: your positioning, not ours
Every asset manager and GP has developed a way of talking about their strategy — the language they use to describe their edge, the framing they apply to their risk approach, the narrative they've refined across hundreds of investor conversations. That positioning is deliberate. It should not be flattened by a generic AI that doesn't know the difference between how a systematic macro manager describes its process and how a fundamental long/short does.
DiligenceVault's skill layer operates at two levels. The system level reflects core IR and DDQ conventions — how questions are typically structured, what allocators are probing for, and how responses should be framed to be credible. The firm level is yours: your specific language, your approved narratives, your positioning on the questions that come up most often.
This prompt library is maintained and updated by your team. When your strategy evolves, when your fund terms change, when your ESG policy is refreshed — the skill layer updates with it. Every subsequent DDQ response reflects current positioning, not last year's language.
The result is responses that sound like they were written by your best IR professional — not by a tool that doesn't know your firm.
Autofill: answered, and flagged
DDQ and RFP formats are not standardised. Every allocator has their own template, their own section logic, their own way of asking what is often the same underlying question. An IR team responding to ten DDQs in a quarter is navigating ten different structures, reformatting the same answers into ten different shapes.
DiligenceVault's autofill layer maps each incoming question to the relevant source material and skill context — regardless of how the question is worded or where it sits in the document. It then generates a response, cites the source, and flags any question where the available material is insufficient to answer with confidence.
The distinction between "drafted" and "review-ready" matters enormously in practice. A draft that requires substantial editing before submission is not a time saving — it is a time shift. The IR professional still does the same work, just later in the process and under more pressure.
Human in the loop: where judgment still belongs
DDQ responses contain two types of content, and they should be handled differently.
The first is factual: fund terms, performance figures, AUM, team biographies, regulatory status, fee structures. These answers exist in verified source documents. They should be retrieved accurately, cited precisely, and presented consistently. This is what the system handles — and where human involvement in the drafting process adds no value, only risk of copy-paste error.
The second is interpretive: how the firm characterises its competitive positioning, how it responds to a sensitive question about a period of underperformance, how it frames a structural change in the team. These answers require the judgment of someone who understands the firm, the relationship with the specific investor, and the context of the question being asked.
Export: in the format that gets read
A completed DDQ response that needs to be reformatted before submission has not saved time — it has moved the work.
DiligenceVault exports directly into the investor's own template where one exists, or into the firm's preferred output format. For RFPs with fixed structure, responses populate into the document exactly as submitted. For DDQs with proprietary formats, the output matches the investor's layout — no reformatting, no copy-paste, no version reconciliation at the end.
The output is submission-ready. That is the standard the export function is held to.
What success looks like
We're often asked how we measure success for DDQ and RFP workflows. The answer isn't response time. It's what the allocator thinks when they read it.
Success also extends beyond the individual response.
A record of every DDQ and RFP submitted, with the source behind every answer. A consistency audit trail that holds up if an allocator compares this year's response to last year's. An IR team that spends its time on investor relationships and strategic communication — not on reformatting spreadsheets at 11pm before a submission deadline.
The firms that will get the most from AI in the DDQ and RFP process are not the ones chasing speed. They are the ones who recognise that allocator trust is built on consistency, and that consistency requires a system — not a heroic individual effort every time a DDQ lands in the inbox.
That is the system DiligenceVault has built for IR and RFP teams.
Not faster DDQ completion.
Accurate, consistent responses — every time they're asked.